浅谈前端面筋(浏览器篇)
从输入 URL 到页面加载的全过程
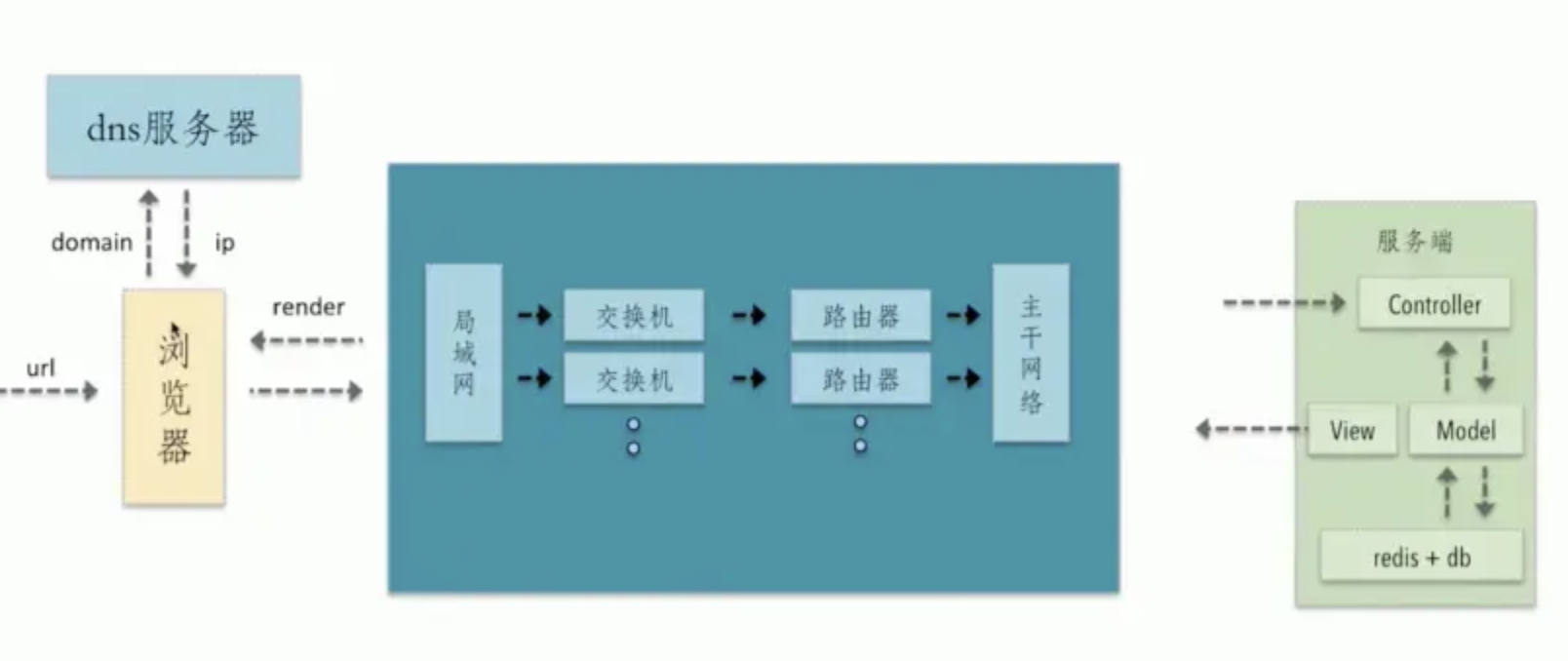
在浏览器中输入 URL。
查找 DNS 缓存
- 浏览器缓存:浏览器会记录 DNS 一段时间,因此,只是第一个地方解析 DNS 请求;
- 操作系统缓存:如果在浏览器缓存中不包含这个记录,则会使系统调用操作系统, 获取操作系统的记录(保存最近的 DNS 查询缓存);
- 路由器缓存:如果上述两个步骤均不能成功获取 DNS 记录,继续搜索路由器缓存;
- ISP 缓存:若上述均失败,继续向 ISP 搜索。
DNS 域名解析:浏览器向 DNS 服务器发起请求,解析该 URL 中的域名对应的 IP 地址。DNS 服务器是基于 UDP 的,因此会用到 UDP 协议。
建立 TCP 连接:解析出 IP 地址后,根据 IP 地址和默认 80 端口,和服务器建立 TCP 连接。
发起 HTTP 请求:浏览器发起读取文件的 HTTP 请求,该请求报文作为 TCP 三次握手的第三次数据发送给服务器
服务器响应请求并返回结果:服务器对浏览器请求做出响应,并把对应的 html 文件发送给浏览器
关闭 TCP 连接:通过四次挥手释放 TCP 连接
浏览器渲染(渲染引擎):客户端(浏览器)解析 HTML 内容并渲染出来,浏览器接收到数据包后的解析流程为:
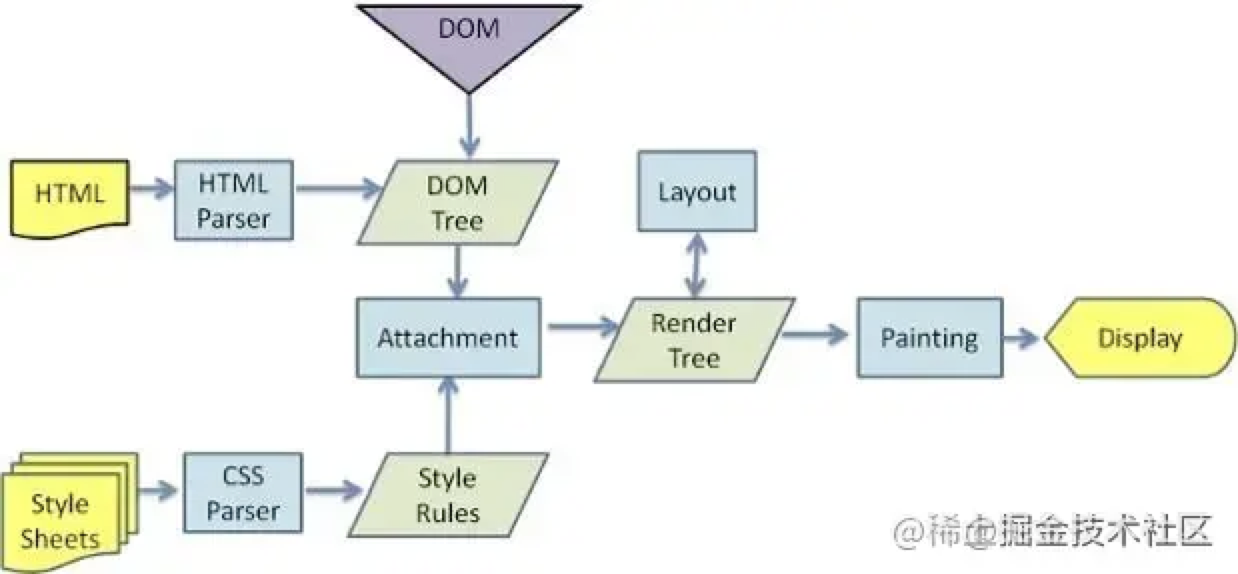
- 构建 DOM 树:词法分析然后解析成 DOM 树(dom tree),是由 dom 元素及属性节点组成,树的根是 document 对象
- 构建 CSS 规则树:生成 CSS 规则树(CSS Rule Tree)
- 构建 render 树:Web 浏览器将 DOM 和 CSSOM 结合,并构建出渲染树(render tree)
- 布局(Layout):计算出每个节点在屏幕中的位置
- 绘制(Painting):即遍历 render 树,并使用 UI 后端层绘制每个节点。
JS 引擎解析过程(具体看另一篇文章:js 引擎解析详解)
- 语法检查
- 预编译
- 执行
浏览器重绘与重排
- 重排/回流(Reflow):当 DOM 的变化影响了元素的几何信息,浏览器需要重新计算元素的几何属性,将其安放在界面中的正确位置,这个过程叫做重排。表现为重新生成布局,重新排列元素。
- 重绘(Repaint): 当一个元素的外观发生改变,但没有改变布局,重新把元素外观绘制出来的过程,叫做重绘。表现为某些元素的外观被改变
- 『重绘』不一定会出现『重排』,『重排』必然会出现『重绘』
如何出发重排和重绘
任何改变用来构建渲染树的信息都会导致一次重排或重绘:
- 添加、删除、更新 DOM 节点
- 通过 display: none 隐藏一个 DOM 节点-触发重排和重绘
- 通过 visibility: hidden 隐藏一个 DOM 节点-只触发重绘,因为没有几何变化
- 移动或者给页面中的 DOM 节点添加动画
- 添加一个样式表,调整样式属性
- 用户行为,例如调整窗口大小,改变字号,或者滚动。
如何避免重绘或者重排
- 集中改变样式,不要一条一条地修改 DOM 的样式。
- 不要把 DOM 结点的属性值放在循环里当成循环里的变量。
- 为动画的 HTML 元件使用 fixed 或 absoult 的 position,那么修改他们的 CSS 是不会 reflow 的。
- 不使用 table 布局。因为可能很小的一个小改动会造成整个 table 的重新布局。
- 尽量只修改 position:absolute 或 fixed 元素,对其他元素影响不大
- 动画开始 GPU 加速,translate 使用 3D 变化
- 提升为合成层
浏览器缓存 强制缓存&协商缓存
强制缓存
强制缓存就是向浏览器缓存查找该请求结果,并根据该结果的缓存规则来决定是否使用该缓存结果的过程。当浏览器向服务器发起请求时,服务器会将缓存规则放入 HTTP 响应报文的 HTTP 头中和请求结果一起返回给浏览器,控制强制缓存的字段分别是 Expires 和 Cache-Control,其中 Cache-Control 优先级比 Expires 高。
强制缓存的情况主要有三种(暂不分析协商缓存过程),如下:- 不存在该缓存结果和缓存标识,强制缓存失效,则直接向服务器发起请求(跟第一次发起请求一致)。
- 存在该缓存结果和缓存标识,但该结果已失效,强制缓存失效,则使用协商缓存。
- 存在该缓存结果和缓存标识,且该结果尚未失效,强制缓存生效,直接返回该结果
协商缓存
协商缓存就是强制缓存失效后,浏览器携带缓存标识向服务器发起请求,由服务器根据缓存标识决定是否使用缓存的过程,同样,协商缓存的标识也是在响应报文的 HTTP 头中和请求结果一起返回给浏览器的,控制协商缓存的字段分别有:Last-Modified / If-Modified-Since 和 Etag / If-None-Match,其中 Etag / If-None-Match 的优先级比 Last-Modified / If-Modified-Since 高。协商缓存主要有以下两种情况:- 协商缓存生效,返回 304
- 协商缓存失效,返回 200 和请求结果结果
介绍一下 304 过程
- 浏览器请求资源时首先命中资源的 Expires 和 Cache-Control,Expires 受限于本地时间,如果修改了本地时间,可能会造成缓存失效,可以通过 Cache-control: max-age 指定最大生命周期,状态仍然返回 200,但不会请求数据,在浏览器中能明显看到 from cache 字样。
- 强缓存失效,进入协商缓存阶段,首先验证 ETag ,ETag 可以保证每一个资源是唯一的,资源变化都会导致 ETag 变化。服务器根据客户端上送的 If-None-Match 值来判断是否命中缓存。
- 协商缓存 Last-Modify/If-Modify-Since 阶段,客户端第一次请求资源时,服务服返回的 header 中会加上 Last-Modify,Last-modify 是一个时间标识该资源的最后修改时间。再次请求该资源时,request 的请求头中会包含 If-Modify-Since,该值为缓存之前返回的 Last-Modify。服务器收到 If-Modify-Since 后,根据资源的最后修改时间判断是否命中缓存。
1 | res.setHeader('Cache-Control', 'no-cache') |
说一下进程、线程和协程
进程是一个具有一定独立功能的程序在一个数据集上的一次动态执行的过程,是操作系统进行资源分配和调度的一个独立单位,是应用程序运行的载体。进程是一种抽象的概念,从来没有统一的标准定义。
线程是程序执行中一个单一的顺序控制流程,是程序执行流的最小单元,是处理器调度和分派的基本单位。一个进程可以有一个或多个线程,各个线程之间共享程序的内存空间(也就是所在进程的内存空间)。一个标准的线程由线程 ID、当前指令指针(PC)、寄存器和堆栈组成。而进程由内存空间(代码、数据、进程空间、打开的文件)和一个或多个线程组成。
协程,英文 Coroutines,是一种基于线程之上,但又比线程更加轻量级的存在,这种由程序员自己写程序来管理的轻量级线程叫做『用户空间线程』,具有对内核来说不可见的特性。
进程和线程的区别与联系
【区别】:
- 调度:线程作为调度和分配的基本单位,进程作为拥有资源的基本单位;
- 并发性:不仅进程之间可以并发执行,同一个进程的多个线程之间也可并发执行;
- 拥有资源:进程是拥有资源的一个独立单位,线程不拥有系统资源,但可以访问隶属于进程的资源。
- 系统开销:在创建或撤消进程时,由于系统都要为之分配和回收资源,导致系统的开销明显大于创建或撤消线程时的开销。但是进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个进程死掉就等于所有的线程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。
【联系】:
- 一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程;
- 资源分配给进程,同一进程的所有线程共享该进程的所有资源;
- 处理机分给线程,即真正在处理机上运行的是线程;
- 线程在执行过程中,需要协作同步。不同进程的线程间要利用消息通信的办法实现同步。





